
The term “Consistent Hashing” combines a sense of sophistication with a hint of complexity. It’s a mechanism designed to manage load efficiently in distributed systems, ensuring performance and resiliency as nodes are added or removed. In this article, I’ll explain consistent hashing using a simple bookshelf analogy, making the concept easier to understand.
At the end of this article you should have a clear understanding of:
- Hashing
- Hash Tables
- Collision
- Rehashing Problem
- Consistent Hashing
- Virtual Node
- Use cases
The analogy
Imagine you are organizing a library with 10 books and have 3 shelves to arrange them. You need to distribute the books so that each shelf is easy to search and none are overloaded, ensuring a balanced and efficient system for finding any book quickly.
Hashing
At the time of writing, these are the top 10 fiction books according to Good Reads. I just realized I have read only two of these. Time to gather some motivation and read a few more from these.
| The Hobbit | Crimen y castigo |
| Dune | A Gentleman in Moscow |
| 1984 | The Lord of the Rings |
| East of Eden | Catch-22 |
| Slaughterhouse-Five | The Kite Runner |
If we distribute the books randomly across the shelves, finding a specific book by name would require scanning each book until we locate the one we want. In the worst case, this means checking all 10 books, resulting in a time complexity of O(n). However, if we could assign each book a unique code or number, we could arrange them more efficiently. We’ll explore how this method improves search efficiency as we progress in the article.
In a very simple world I would assign each book a number from 0-9.
| Book Name | Book Code |
| The Hobbit | 0 |
| Crimen y castigo | 1 |
| Dune | 2 |
| A Gentleman in Moscow | 3 |
| 1984 | 4 |
| The Lord of the Rings | 5 |
| East of Eden | 6 |
| Catch-22 | 7 |
| Slaughterhouse-Five | 8 |
| The Kite Runner | 9 |
This mechanism of converting an input of arbitrary size to an output generally an integer is called Hashing. The output is typically in a predefined range. The output code is called the Hash Key. And the function which does the transformation is called Hash Function. A hash function is denoted by H(x).
So, H(“The Hobbit”) = 0
For simplicity I have assumed the hash keys are generated in a predefined range of 0-9.
Hash Tables
However, simply assigning a code to each book doesn’t make the search more efficient. We need to store these hash codes in a way that easily maps each code to its corresponding book. With our analogy of 3 shelves, let’s define our range of hash keys from 0 to 2. To achieve this, we can use a basic hash function known as the Division Method.
H(x) = x mod n, where x is the book number and n is number of shelvesSo, our hash keys based on the above hash function will be like below.
| Book Name | Hash Function | Hash Key |
| The Hobbit | 0 % 3 | 0 |
| Crimen y castigo | 1 % 3 | 1 |
| Dune | 2 % 3 | 2 |
| A Gentleman in Moscow | 3 % 3 | 0 |
| 1984 | 4 % 3 | 1 |
| The Lord of the Rings | 5 % 3 | 2 |
| East of Eden | 6 % 3 | 0 |
| Catch-22 | 7 % 3 | 1 |
| Slaughterhouse-Five | 8 % 3 | 2 |
| The Kite Runner | 9 % 3 | 0 |
If we now map each book it’s corresponding hash key, we get the below table. This table we have got now is our Hash Table.
| Hash Key | Books |
| 0 | The Hobbit, A Gentleman in Moscow, East of Eden, The Kite Runner |
| 1 | Crimen y castigo, 1984, Catch-22 |
| 2 | Dune, The Lord of the Rings, Slaughterhouse-Five |
Collision

Now that we have our hash table, how does it help? When searching for a book, we apply the same hash function to find the corresponding hash key (shelf). This limits our search to just one shelf rather than all of them. In our example, the search complexity reduces to O(3) instead of O(10), significantly speeding up data retrieval.
As you might have already noticed, different inputs may result into same hash keys. This phenomenon is called collision. A good hash function should be able to evenly distribute the data across hash keys. Each hash key which holds multiple items is called a bucket.
The Rehashing Problem
At this point, our books are well-organized, and it’s easy to find a book on one of the 3 shelves. But what happens if we add a fourth shelf? With 4 shelves, our hash function changes, altering how the books are distributed across the shelves. Here’s what the new arrangement looks like.
| Book Name | Hash Function | Hash Key |
| The Hobbit | 0 % 4 | 0 |
| Crimen y castigo | 1 % 4 | 1 |
| Dune | 2 % 4 | 2 |
| A Gentleman in Moscow | 3 % 4 | 3 |
| 1984 | 4 % 4 | 0 |
| The Lord of the Rings | 5 % 4 | 1 |
| East of Eden | 6 % 4 | 2 |
| Catch-22 | 7 % 4 | 3 |
| Slaughterhouse-Five | 8 % 4 | 0 |
| The Kite Runner | 9 % 4 | 1 |
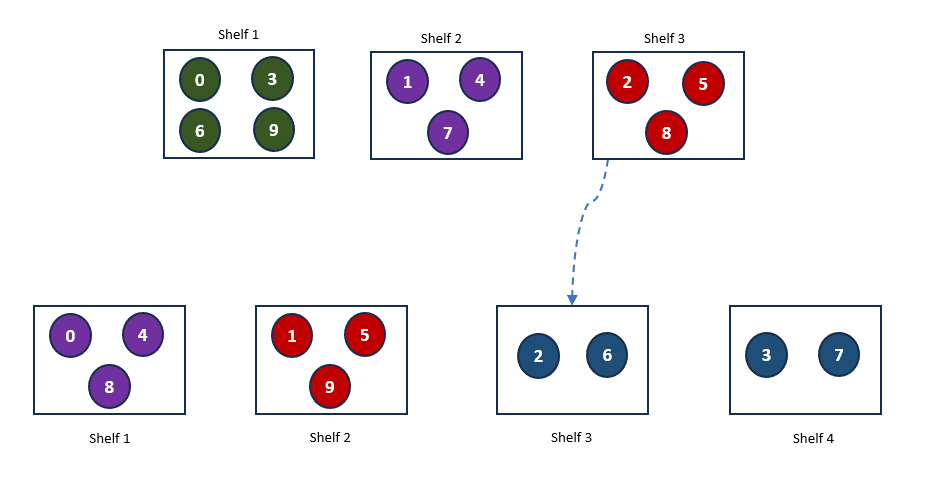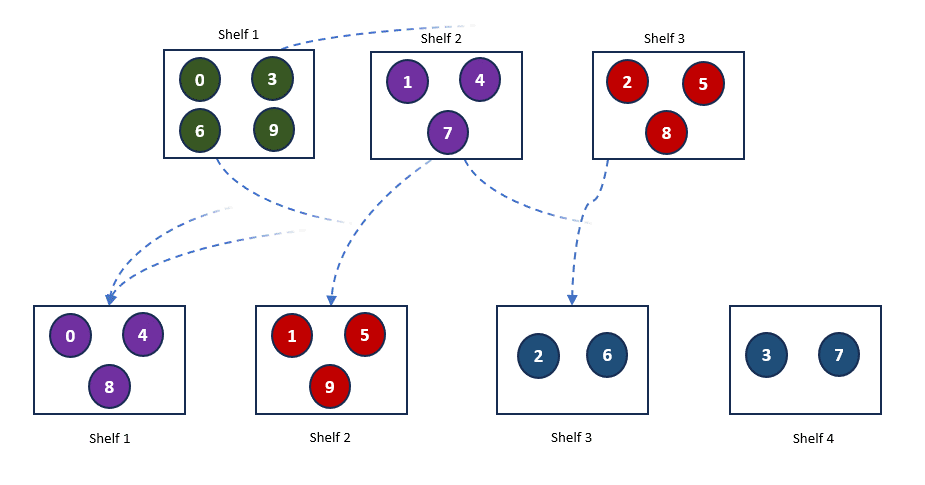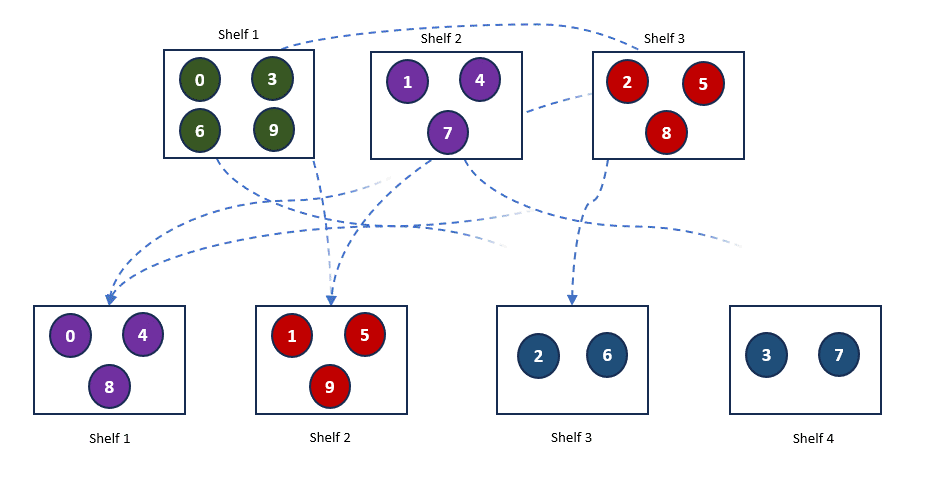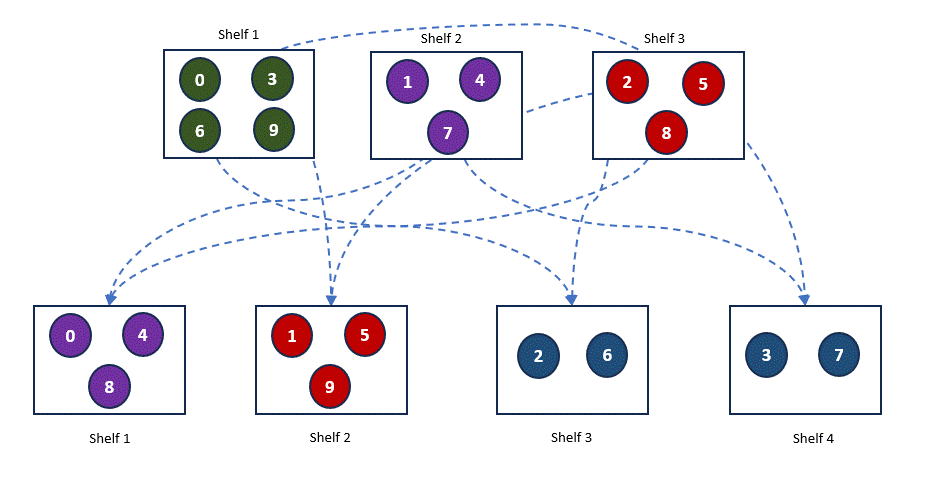
As you can see, adding a new shelf requires a significant rearrangement of the books, which is not ideal. This situation is common in distributed systems, where servers may be added or removed based on demand. This process, known as rehashing, forces the regeneration of hash keys and can lead to major reorganizations. Such frequent changes are counterproductive and can negatively impact system performance due to the overhead involved in constantly rearranging data.
Consistent Hashing
This is where consistent hashing comes into play. Although the term might sound complex, it’s actually quite simple and remarkably effective. The essence of consistent hashing is to make the distribution of books independent of the number of shelves available. To achieve this, let’s map all possible hash codes onto an array.

Now, we will apply a small trick. We will transform this array into a ring. This abstract ring is known as hash ring.
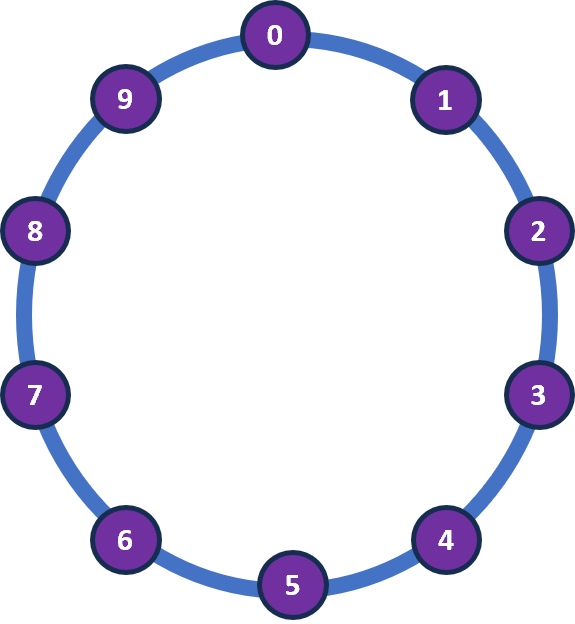
Now, we need to map the shelves appropriately along the ring. Previously, we applied the hash function only to the books, but now we need to apply the hash function to the shelves as well. The hash outcome for each shelf will also fall within the range of 0-9, as our hash function produces results within this range. For simplicity, we’ll use the shelf name to generate the hash. Let’s assume the following hash outcomes:
| Shelf | Hash |
| H(Shelf 1) | 2 |
| H(Shelf 2) | 5 |
| H(Shelf 3) | 8 |
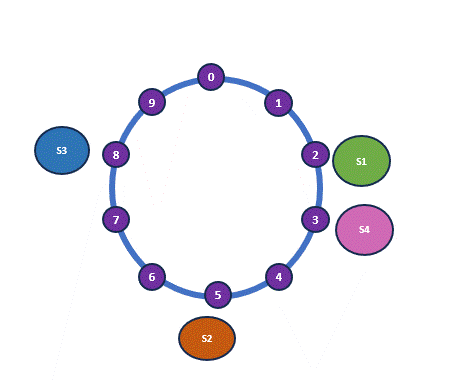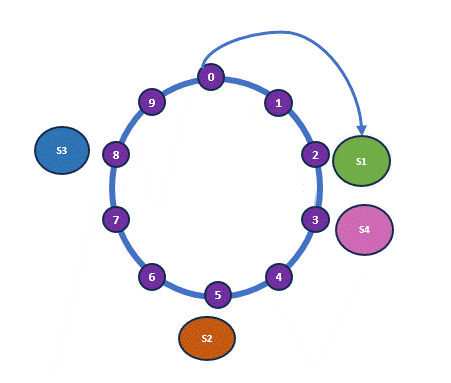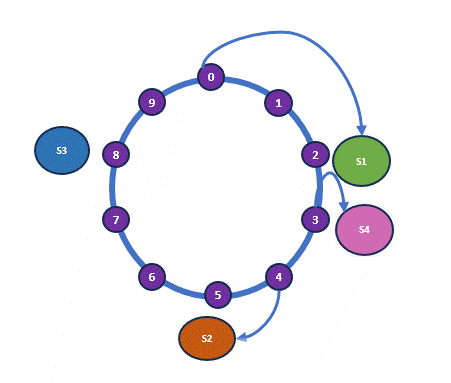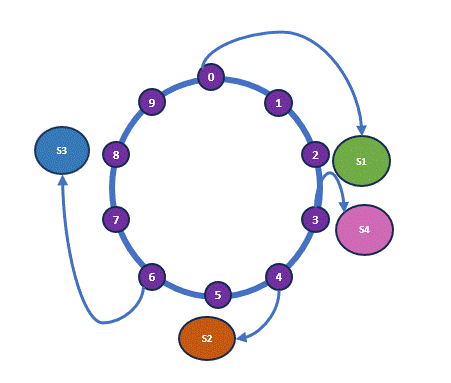
This is a key aspect of consistent hashing. Typically, a hash function is applied to server identifiers, which can be an internal IP address or a combination of various server properties. In our analogy, the shelves represent the servers. The most crucial part of consistent hashing is how the items are placed: when arranging the books, we move clockwise around the ring and place each book on the nearest available shelf.
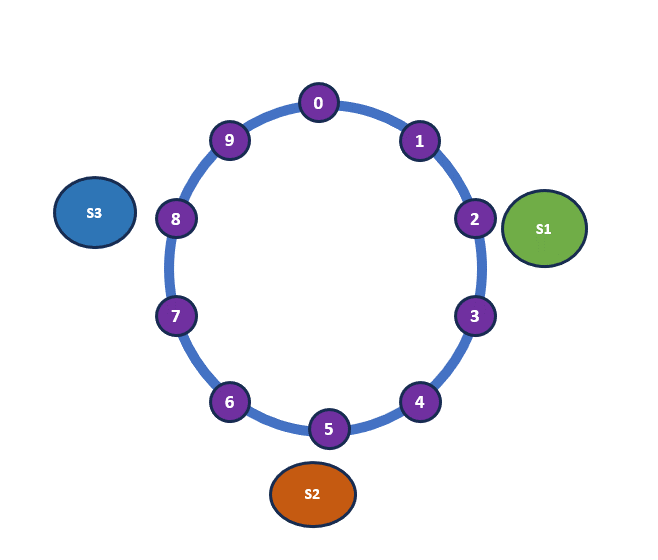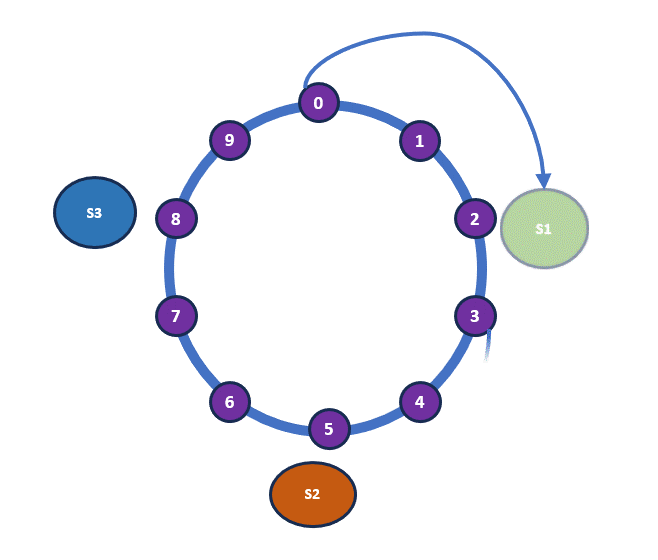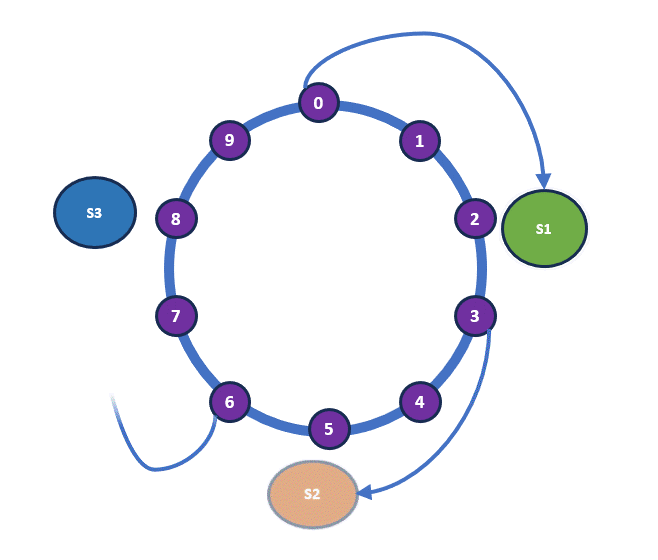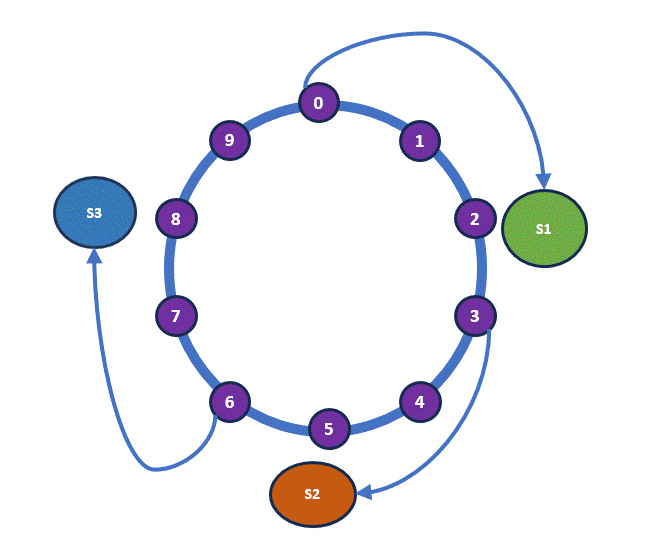
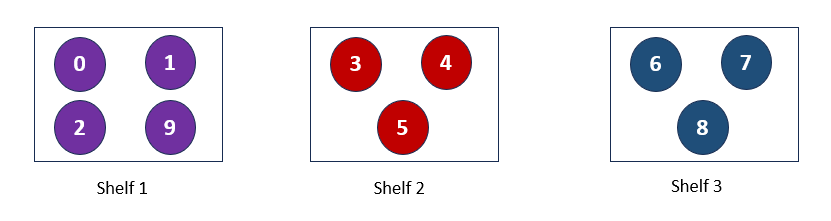
So book 0, 1, 2 moves to S1. Book 3, 4, 5 moves to S2 and so on. Below is the current arrangement of the books at the moment.
Now, let’s simulate the addition of another shelf. Let’s assume that the hash value for Shelf 4, H(Shelf 4) = 3. With this addition, Book 3, which was previously allocated to Shelf 2, will now be allocated to Shelf 4, as it is the nearest shelf. However, nothing else changes. Below is our new hash ring and the updated allocation.
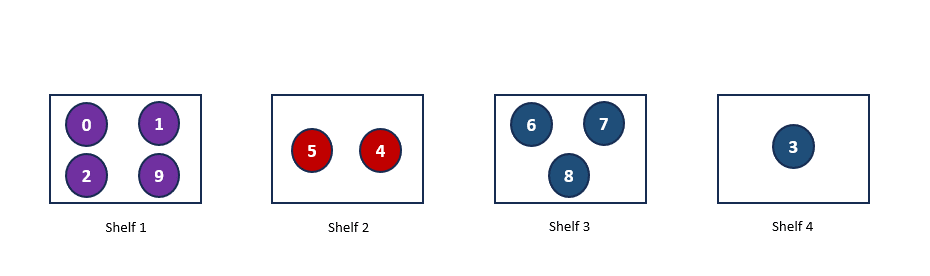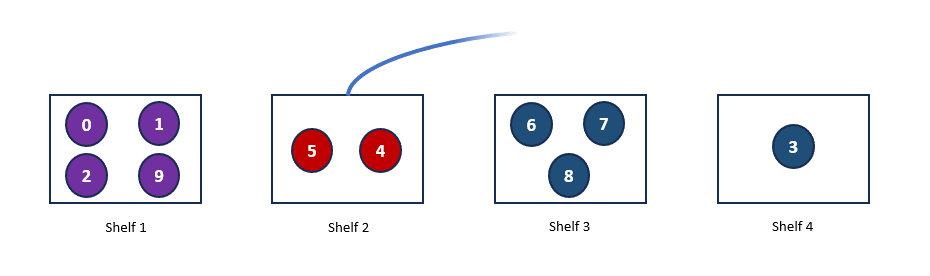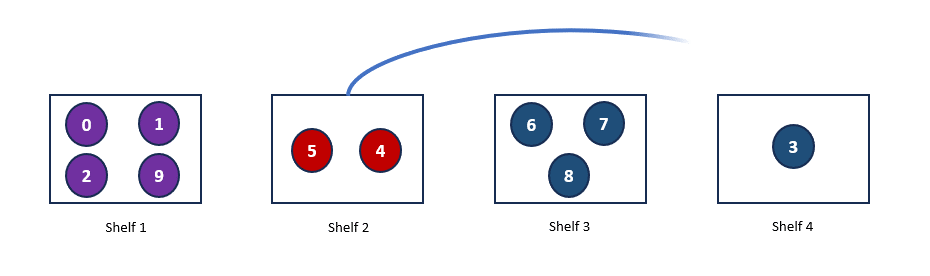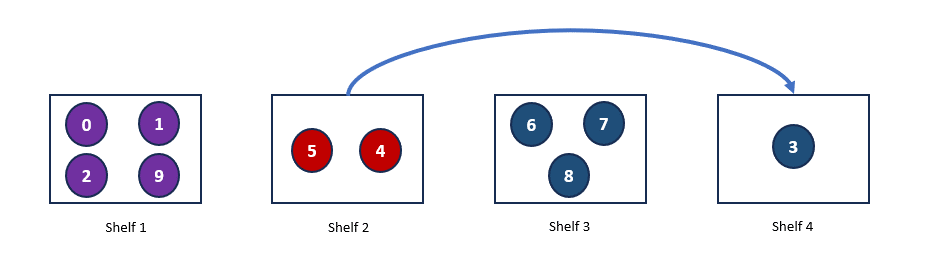
As you can see, some rearrangement is still necessary, but it’s minimal. This hashing mechanism, where the load is balanced independently of the number of servers by mapping data objects onto an abstract ring, is known as consistent hashing.
Is this the perfect solution?
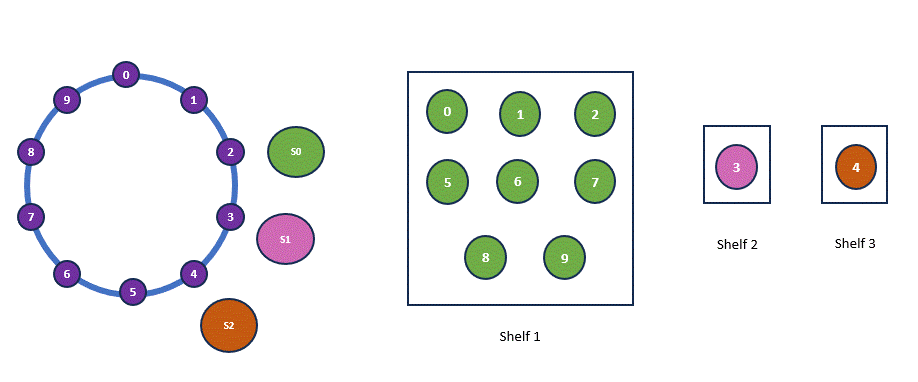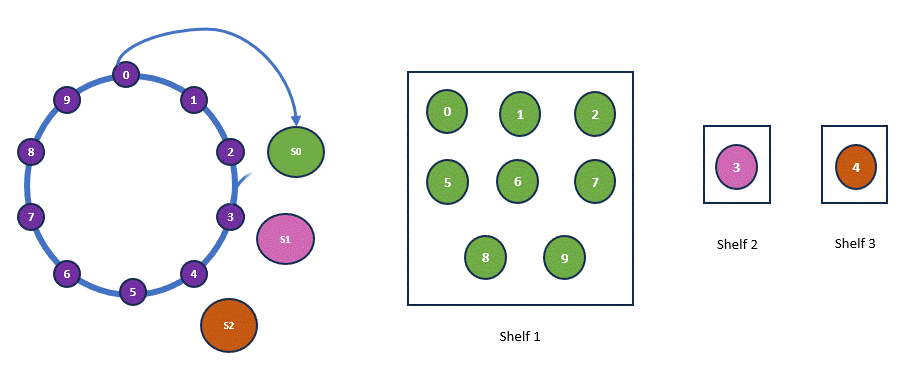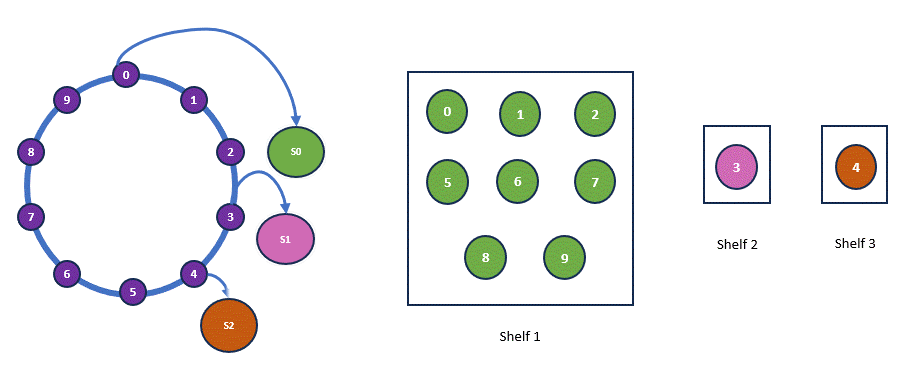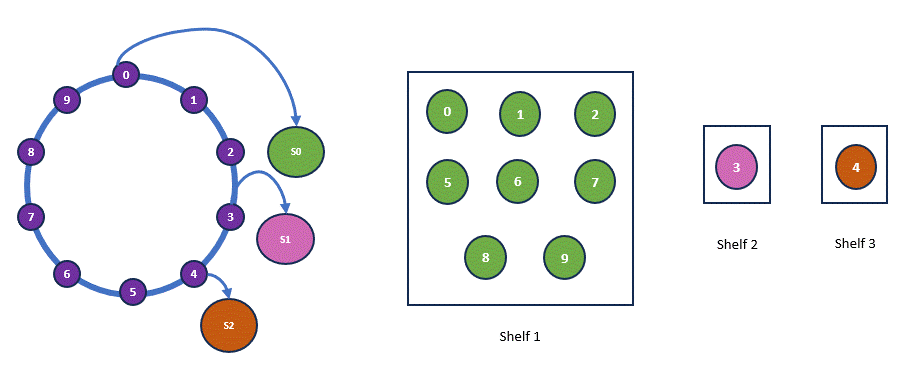
You may have noticed that I conveniently assumed evenly distributed hash outcomes around the ring, creating the illusion of a nearly perfect distribution. However, in real-world scenarios, this is rarely the case. Consider a different set of hash outcomes—this could lead to a significantly skewed distribution. Below is an example of a new hash ring and allocation. So clearly this is not the perfect solution.
| Shelf | Old Hash | New Hash |
| H(Shelf 1) | 2 | 2 |
| H(Shelf 2) | 5 | 3 |
| H(Shelf 3) | 8 | 4 |
Virtual Node
Let’s increase our number of books from 10 to 100. With this larger set, the issue of skewed distribution becomes even more magnified. The reason this happens is because the hash outcomes are random. One way to mitigate the effect of uneven distribution is by increasing the number of shelves. But that may not be cost effective. So how about we divide the same number of shelves into more partitions?

Each partition now acts as a virtual node. Most consistent hashing algorithms achieve this by hashing the same server multiple times with different hash functions. The resulting range of hash outcomes defines each server’s range. For example, S1 could be divided into S1-1, S1-2, S1-3, and so on. If we plot this on our hash ring, it would look like the diagram below.

Our shelves are now more evenly distributed, which allows our books to be uniformly arranged. This improves the resiliency of the shelves and speeds up the search process. All that without increasing the cost, as we maintained the same number of shelves.
Use cases
Consistent hashing is a widely used concept. Some of the popular use cases are
- Distributed Caching systems like Memcached
- Cassandra and many other distributed DBs for data partitioning
- Various cloud load balancers
Conclusion
I’ve used a bookshelf analogy to explain the concept of consistent hashing. Relating technical concepts to real-life scenarios often helps me grasp them more easily, and I hope this analogy will help you understand it better as well.